
艾銻無限為您整理:IP,你必知必會的十個問題
2020-02-14 17:11 作者:艾銻無限 瀏覽量:
迎戰疫情,艾銻無限用愛與您同行
為中國中小企業提供免費IT外包服務

為中國中小企業提供免費IT外包服務
這次的肺炎疫情對中國的中小企業將會是沉重的打擊,據釘釘和微信兩個辦公平臺數據統計現有2億左右的人在家遠程辦公,那么對于中小企業的員工來說不懂IT技術將會讓他們面臨的最大挑戰和困難。
電腦不亮了怎么辦?系統藍屏如何處理?辦公室的電腦在家如何連接?網絡應該如何設置?VPN如何搭建?數據如何對接?服務器如何登錄?數據安全如何保證?數據如何存儲?視頻會議如何搭建?業務系統如何開啟等等一系列的問題,都會困擾著并非技術出身的您。

好消息是當您看到這篇文章的時候,就不用再為上述的問題而苦惱,您只需撥打艾銻無限的全國免費熱線電話:400 650 7820,就會有我們的遠程工程師為您解決遇到的問題,他們可以遠程幫您處理遇到的一些IT技術難題。
如遇到免費熱線占線,您還可以撥打我們的24小時值班經理電話:15601064618或技術經理的電話:13041036957,我們會在第一時間接聽您的來電,為您提供適合的解決方案,讓您無論在家還是在企業都能無憂辦公。
那艾銻無限具體能為您的企業提供哪些服務呢?

第一版塊是保障性IT外包服務:如電腦設備運維,辦公設備運維,網絡設備運維,服務器運維等綜合性企業IT設備運維服務。
第二版塊是功能性互聯網外包服務:如網站開發外包,小程序開發外包,APP開發外包,電商平臺開發外包,業務系統的開發外包和后期的運維外包服務。
第三版塊是增值性云服務外包:如企業郵箱上云,企業網站上云,企業存儲上云,企業APP小程序上云,企業業務系統上云,阿里云產品等后續的云運維外包服務。
您要了解更多服務也可以登錄艾銻無限的官網:www.bjitwx.com查看詳細說明,在疫情期間,您企業遇到的任何困境只要找到艾銻無限,能免費為您提供服務的我們絕不收一分錢,我們全體艾銻人承諾此活動直到中國疫情結束,我
們將這次活動稱為——春雷行動。
以下還有我們為您提供的一些技術資訊,以便可以幫助您更好的了解相關的IT知識,幫您渡過疫情中辦公遇到的困難和挑戰,艾銻無限愿和中國中小企業一起共進退,因為我們相信萬物同體,能量合一,只要我們一起齊心協
力,一定會成功。再一次祝福您和您的企業,戰勝疫情,您和您的企業一定行。
艾銻無限為您整理:TCP/IP,你必知必會的十個問題
本文整理了一些TCP/IP協議簇中需要必知必會的十大問題,既是面試高頻問題,又是程序員必備基礎素養。
一、TCP/IP模型
TCP/IP協議模型(Transmission Control Protocol/Internet Protocol),包含了一系列構成互聯網基礎的網絡協議,是Internet的核心協議。
基于TCP/IP的參考模型將協議分成四個層次,它們分別是鏈路層、網絡層、傳輸層和應用層。下圖表示TCP/IP模型與OSI模型各層的對照關系。
TCP/IP協議族按照層次由上到下,層層包裝。最上面的是應用層,這里面有http,ftp,等等我們熟悉的協議。而第二層則是傳輸層,著名的TCP和UDP協議就在這個層次。
第三層是網絡層,IP協議就在這里,它負責對數據加上IP地址和其他的數據以確定傳輸的目標。第四層是數據鏈路層,這個層次為待傳送的數據加入一個以太網協議頭,并進行CRC編碼,為***的數據傳輸做準備。
上圖清楚地表示了TCP/IP協議中每個層的作用,而TCP/IP協議通信的過程其實就對應著數據入棧與出棧的過程。入棧的過程,數據發送方每層不斷地封裝首部與尾部,添加一些傳輸的信息,確保能傳輸到目的地。出棧的過程,數據接收方每層不斷地拆除首部與尾部,得到最終傳輸的數據。
上圖以HTTP協議為例,具體說明。
二、數據鏈路層
物理層負責0、1比特流與物理設備電壓高低、光的閃滅之間的互換。 數據鏈路層負責將0、1序列劃分為數據幀從一個節點傳輸到臨近的另一個節點,這些節點是通過MAC來唯一標識的(MAC,物理地址,一個主機會有一個MAC地址)。
封裝成幀:把網絡層數據報加頭和尾,封裝成幀,幀頭中包括源MAC地址和目的MAC地址。
透明傳輸:零比特填充、轉義字符。
可靠傳輸:在出錯率很低的鏈路上很少用,但是無線鏈路WLAN會保證可靠傳輸。
差錯檢測(CRC):接收者檢測錯誤,如果發現差錯,丟棄該幀。
三、網絡層
1. IP協議
IP協議是TCP/IP協議的核心,所有的TCP,UDP,IMCP,IGMP的數據都以IP數據格式傳輸。要注意的是,IP不是可靠的協議,這是說,IP協議沒有提供一種數據未傳達以后的處理機制,這被認為是上層協議:TCP或UDP要做的事情。
(1) IP地址
在數據鏈路層中我們一般通過MAC地址來識別不同的節點,而在IP層我們也要有一個類似的地址標識,這就是IP地址。
32位IP地址分為網絡位和地址位,這樣做可以減少路由器中路由表記錄的數目,有了網絡地址,就可以限定擁有相同網絡地址的終端都在同一個范圍內,那么路由表只需要維護一條這個網絡地址的方向,就可以找到相應的這些終端了。
A類IP地址:0.0.0.0~127.255.255.255
B類IP地址:128.0.0.0~191.255.255.255
C類IP地址:192.0.0.0~239.255.255.255
(2) IP協議頭
這里只介紹:八位的TTL字段。這個字段規定該數據包在穿過多少個路由之后才會被拋棄。某個IP數據包每穿過一個路由器,該數據包的TTL數值就會減少1,當該數據包的TTL成為零,它就會被自動拋棄。
這個字段的***值也就是255,也就是說一個協議包也就在路由器里面穿行255次就會被拋棄了,根據系統的不同,這個數字也不一樣,一般是32或者是64。
2. ARP及RARP協議
ARP 是根據IP地址獲取MAC地址的一種協議。
ARP(地址解析)協議是一種解析協議,本來主機是完全不知道這個IP對應的是哪個主機的哪個接口,當主機要發送一個IP包的時候,會首先查一下自己的ARP高速緩存(就是一個IP-MAC地址對應表緩存)。
如果查詢的IP-MAC值對不存在,那么主機就向網絡發送一個ARP協議廣播包,這個廣播包里面就有待查詢的IP地址,而直接收到這份廣播的包的所有主機都會查詢自己的IP地址,如果收到廣播包的某一個主機發現自己符合條件,那么就準備好一個包含自己的MAC地址的ARP包傳送給發送ARP廣播
的主機。
而廣播主機拿到ARP包后會更新自己的ARP緩存(就是存放IP-MAC對應表的地方)。發送廣播的主機就會用新的ARP緩存數據準備好數據鏈路層的的數據包發送工作。
RARP協議的工作與此相反,不做贅述。
3. ICMP協議
IP協議并不是一個可靠的協議,它不保證數據被送達,那么,自然的,保證數據送達的工作應該由其他的模塊來完成。其中一個重要的模塊就是ICMP(網絡控制報文)協議。ICMP不是高層協議,而是IP層的協議。
當傳送IP數據包發生錯誤。比如主機不可達,路由不可達等等,ICMP協議將會把錯誤信息封包,然后傳送回給主機。給主機一個處理錯誤的機會,這 也就是為什么說建立在IP層以上的協議是可能做到安全的原因。
四、ping
ping可以說是ICMP的***的應用,是TCP/IP協議的一部分。利用“ping”命令可以檢查網絡是否連通,可以很好地幫助我們分析和判定網絡故障。
例如:當我們某一個網站上不去的時候。通常會ping一下這個網站。ping會回顯出一些有用的信息。一般的信息如下:

ping這個單詞源自聲納定位,而這個程序的作用也確實如此,它利用ICMP協議包來偵測另一個主機是否可達。原理是用類型碼為0的ICMP發請 求,受到請求的主機則用類型碼為8的ICMP回應。
ping程序來計算間隔時間,并計算有多少個包被送達。用戶就可以判斷網絡大致的情況。我們可以看到, ping給出來了傳送的時間和TTL的數據。
五、Traceroute
Traceroute是用來偵測主機到目的主機之間所經路由情況的重要工具,也是最便利的工具。
Traceroute的原理是非常非常的有意思,它收到到目的主機的IP后,首先給目的主機發送一個TTL=1的UDP數據包,而經過的***個路由器收到這個數據包以后,就自動把TTL減1,而TTL變為0以后,路由器就把這個包給拋棄了,并同時產生 一個主機不可達的ICMP數據報給主機。主機收到這個數據
報以后再發一個TTL=2的UDP數據報給目的主機,然后刺激第二個路由器給主機發ICMP數據 報。如此往復直到到達目的主機。這樣,traceroute就拿到了所有的路由器IP。

六、TCP/UDP
TCP/UDP都是是傳輸層協議,但是兩者具有不同的特性,同時也具有不同的應用場景,下面以圖表的形式對比分析。
1. 面向報文
面向報文的傳輸方式是應用層交給UDP多長的報文,UDP就照樣發送,即一次發送一個報文。因此,應用程序必須選擇合適大小的報文。若報文太長,則IP層需要分片,降低效率。若太短,會是IP太小。
2. 面向字節流
面向字節流的話,雖然應用程序和TCP的交互是一次一個數據塊(大小不等),但TCP把應用程序看成是一連串的無結構的字節流。TCP有一個緩沖,當應用程序傳送的數據塊太長,TCP就可以把它劃分短一些再傳送。
關于擁塞控制,流量控制,是TCP的重點,后面講解。
TCP和UDP協議的一些應用:
3. 什么時候應該使用TCP?
當對網絡通訊質量有要求的時候,比如:整個數據要準確無誤的傳遞給對方,這往往用于一些要求可靠的應用,比如HTTP、HTTPS、FTP等傳輸文件的協議,POP、SMTP等郵件傳輸的協議。
4. 什么時候應該使用UDP?
當對網絡通訊質量要求不高的時候,要求網絡通訊速度能盡量的快,這時就可以使用UDP。
七、DNS
DNS(Domain Name System,域名系統),因特網上作為域名和IP地址相互映射的一個分布式數據庫,能夠使用戶更方便的訪問互聯網,而不用去記住能夠被機器直接讀取的IP數串。通過主機名,最終得到該主機名對應的IP地址的過程叫做域名解析(或主機名解析)。DNS協議運行在UDP協議之上,
使用端口號53。
八、TCP連接的建立與終止
1. 三次握手
TCP是面向連接的,無論哪一方向另一方發送數據之前,都必須先在雙方之間建立一條連接。在TCP/IP協議中,TCP協議提供可靠的連接服務,連接是通過三次握手進行初始化的。三次握手的目的是同步連接雙方的序列號和確認號并交換 TCP窗口大小信息。
***次握手: 建立連接。客戶端發送連接請求報文段,將SYN位置為1,Sequence Number為x;然后,客戶端進入SYN_SEND狀態,等待服務器的確認;
第二次握手: 服務器收到SYN報文段。服務器收到客戶端的SYN報文段,需要對這個SYN報文段進行確認,設置Acknowledgment Number為x+1(Sequence Number+1);同時,自己自己還要發送SYN請求信息,將SYN位置為1,Sequence Number為y;服務器端將上述所有信息放到一個報文段(即
SYN+ACK報文段)中,一并發送給客戶端,此時服務器進入SYN_RECV狀態;
第三次握手: 客戶端收到服務器的SYN+ACK報文段。然后將Acknowledgment Number設置為y+1,向服務器發送ACK報文段,這個報文段發送完畢以后,客戶端和服務器端都進入ESTABLISHED狀態,完成TCP三次握手。
為什么要三次握手?
為了防止已失效的連接請求報文段突然又傳送到了服務端,因而產生錯誤。
具體例子:“已失效的連接請求報文段”的產生在這樣一種情況下:client發出的***個連接請求報文段并沒有丟失,而是在某個網絡結點長時間的滯留了,以致延誤到連接釋放以后的某個時間才到達server。本來這是一個早已失效的報文段。
但server收到此失效的連接請求報文段后,就誤認為是client再次發出的一個新的連接請求。于是就向client發出確認報文段,同意建立連接。假設不采用“三次握手”,那么只要server發出確認,新的連接就建立了。由于現在client并沒有發出建立連接的請求,因此不會理睬server的確認,也不會向
server發送數據。但server卻以為新的運輸連接已經建立,并一直等待client發來數據。這樣,server的很多資源就白白浪費掉了。
采用“三次握手”的辦法可以防止上述現象發生。例如剛才那種情況,client不會向server的確認發出確認。server由于收不到確認,就知道client并沒有要求建立連接。”
2. 四次揮手
當客戶端和服務器通過三次握手建立了TCP連接以后,當數據傳送完畢,肯定是要斷開TCP連接的啊。那對于TCP的斷開連接,這里就有了神秘的“四次分手”。
***次分手:主機1(可以使客戶端,也可以是服務器端),設置Sequence Number,向主機2發送一個FIN報文段;此時,主機1進入FIN_WAIT_1狀態;這表示主機1沒有數據要發送給主機2了;
第二次分手:主機2收到了主機1發送的FIN報文段,向主機1回一個ACK報文段,Acknowledgment Number為Sequence Number加1;主機1進入FIN_WAIT_2狀態;主機2告訴主機1,我“同意”你的關閉請求;
第三次分手: 主機2向主機1發送FIN報文段,請求關閉連接,同時主機2進入LAST_ACK狀態;
第四次分手:主機1收到主機2發送的FIN報文段,向主機2發送ACK報文段,然后主機1進入TIME_WAIT狀態;主機2收到主機1的ACK報文段以后,就關閉連接;此時,主機1等待2MSL后依然沒有收到回復,則證明Server端已正常關閉,那好,主機1也可以關閉連接了。
(1) 為什么要四次分手?
TCP協議是一種面向連接的、可靠的、基于字節流的運輸層通信協議。
TCP是全雙工模式,這就意味著,當主機1發出FIN報文段時,只是表示主機1已經沒有數據要發送了,主機1告訴主機2,它的數據已經全部發送完畢了;但是,這個時候主機1還是可以接受來自主機2的數據;當主機2返回ACK報文段時,表示它已經知道主機1沒有數據發送了,但是主機2還是可以發送
數據到主機1的;當主機2也發送了FIN報文段時,這個時候就表示主機2也沒有數據要發送了,就會告訴主機1,我也沒有數據要發送了,之后彼此就會愉快的中斷這次TCP連接。
(2) 為什么要等待2MSL?
MSL:報文段***生存時間,它是任何報文段被丟棄前在網絡內的最長時間。
原因有二:
保證TCP協議的全雙工連接能夠可靠關閉。
保證這次連接的重復數據段從網絡中消失。
***點:如果主機1直接CLOSED了,那么由于IP協議的不可靠性或者是其它網絡原因,導致主機2沒有收到主機1***回復的ACK。那么主機2就會在超時之后繼續發送FIN,此時由于主機1已經CLOSED了,就找不到與重發的FIN對應的連接。所以,主機1不是直接進入CLOSED,而是要保持
TIME_WAIT,當再次收到FIN的時候,能夠保證對方收到ACK,***正確的關閉連接。
第二點:如果主機1直接CLOSED,然后又再向主機2發起一個新連接,我們不能保證這個新連接與剛關閉的連接的端口號是不同的。也就是說有可能新連接和老連接的端口號是相同的。一般來說不會發生什么問題,但是還是有特殊情況出現:假設新連接和已經關閉的老連接端口號是一樣的,如果
前一次連接的某些數據仍然滯留在網絡中,這些延遲數據在建立新連接之后才到達主機2,由于新連接和老連接的端口號是一樣的,TCP協議就認為那個延遲的數據是屬于新連接的,這樣就和真正的新連接的數據包發生混淆了。
所以TCP連接還要在TIME_WAIT狀態等待2倍MSL,這樣可以保證本次連接的所有數據都從網絡中消失。
九、TCP流量控制
如果發送方把數據發送得過快,接收方可能會來不及接收,這就會造成數據的丟失。所謂流量控制就是讓發送方的發送速率不要太快,要讓接收方來得及接收。
利用滑動窗口機制可以很方便地在TCP連接上實現對發送方的流量控制。
設A向B發送數據。在連接建立時,B告訴了A:“我的接收窗口是 rwnd = 400 ”(這里的 rwnd 表示 receiver window) 。因此,發送方的發送窗口不能超過接收方給出的接收窗口的數值。請注意,TCP的窗口單位是字節,不是報文段。假設每一個報文段為100字節長,而數據報文段序號的初始值設為
1。大寫ACK表示首部中的確認位ACK,小寫ack表示確認字段的值ack。

從圖中可以看出,B進行了三次流量控制。***次把窗口減少到 rwnd = 300 ,第二次又減到了 rwnd = 100 ,***減到 rwnd = 0 ,即不允許發送方再發送數據了。這種使發送方暫停發送的狀態將持續到主機B重新發出一個新的窗口值為止。B向A發送的三個報文段都設置了 ACK = 1 ,只有在ACK=1時確
認號字段才有意義。
TCP為每一個連接設有一個持續計時器(persistence timer)。只要TCP連接的一方收到對方的零窗口通知,就啟動持續計時器。若持續計時器設置的時間到期,就發送一個零窗口控測報文段(攜1字節的數據),那么收到這個報文段的一方就重新設置持續計時器。
十、TCP擁塞控制
1. 慢開始和擁塞避免
發送方維持一個擁塞窗口 cwnd ( congestion window )的狀態變量。擁塞窗口的大小取決于網絡的擁塞程度,并且動態地在變化。發送方讓自己的發送窗口等于擁塞窗口。
發送方控制擁塞窗口的原則是:只要網絡沒有出現擁塞,擁塞窗口就再增大一些,以便把更多的分組發送出去。但只要網絡出現擁塞,擁塞窗口就減小一些,以減少注入到網絡中的分組數。
(1) 慢開始算法:
當主機開始發送數據時,如果立即所大量數據字節注入到網絡,那么就有可能引起網絡擁塞,因為現在并不清楚網絡的負荷情況。
因此,較好的方法是 先探測一下,即由小到大逐漸增大發送窗口,也就是說,由小到大逐漸增大擁塞窗口數值。
通常在剛剛開始發送報文段時,先把擁塞窗口 cwnd 設置為一個***報文段MSS的數值。而在每收到一個對新的報文段的確認后,把擁塞窗口增加至多一個MSS的數值。用這樣的方法逐步增大發送方的擁塞窗口 cwnd ,可以使分組注入到網絡的速率更加合理。
每經過一個傳輸輪次,擁塞窗口 cwnd 就加倍。一個傳輸輪次所經歷的時間其實就是往返時間RTT。不過“傳輸輪次”更加強調:把擁塞窗口cwnd所允許發送的報文段都連續發送出去,并收到了對已發送的***一個字節的確認。
另外,慢開始的“慢”并不是指cwnd的增長速率慢,而是指在TCP開始發送報文段時先設置cwnd=1,使得發送方在開始時只發送一個報文段(目的是試探一下網絡的擁塞情況),然后再逐漸增大cwnd。
為了防止擁塞窗口cwnd增長過大引起網絡擁塞,還需要設置一個慢開始門限ssthresh狀態變量。慢開始門限ssthresh的用法如下:
當 cwnd < ssthresh 時,使用上述的慢開始算法。
當 cwnd > ssthresh 時,停止使用慢開始算法而改用擁塞避免算法。
當 cwnd = ssthresh 時,既可使用慢開始算法,也可使用擁塞控制避免算法。
(2) 擁塞避免
讓擁塞窗口cwnd緩慢地增大,即每經過一個往返時間RTT就把發送方的擁塞窗口cwnd加1,而不是加倍。這樣擁塞窗口cwnd按線性規律緩慢增長,比慢開始算法的擁塞窗口增長速率緩慢得多。
無論在慢開始階段還是在擁塞避免階段,只要發送方判斷網絡出現擁塞(其根據就是沒有收到確認),就要把慢開始門限ssthresh設置為出現擁塞時的發送 方窗口值的一半(但不能小于2)。然后把擁塞窗口cwnd重新設置為1,執行慢開始算法。
這樣做的目的就是要迅速減少主機發送到網絡中的分組數,使得發生 擁塞的路由器有足夠時間把隊列中積壓的分組處理完畢。
如下圖,用具體數值說明了上述擁塞控制的過程。現在發送窗口的大小和擁塞窗口一樣大。
2. 快重傳和快恢復
(1) 快重傳
快重傳算法首先要求接收方每收到一個失序的報文段后就立即發出重復確認(為的是使發送方及早知道有報文段沒有到達對方)而不要等到自己發送數據時才進行捎帶確認。
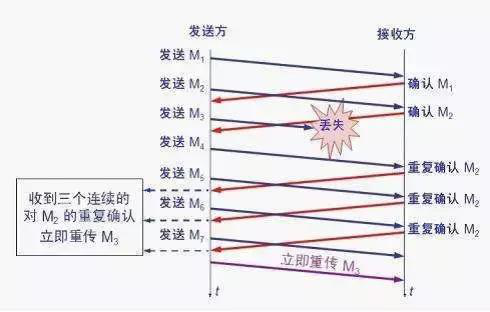
接收方收到了M1和M2后都分別發出了確認。現在假定接收方沒有收到M3但接著收到了M4。
顯然,接收方不能確認M4,因為M4是收到的失序報文段。根據 可靠傳輸原理,接收方可以什么都不做,也可以在適當時機發送一次對M2的確認。
但按照快重傳算法的規定,接收方應及時發送對M2的重復確認,這樣做可以讓 發送方及早知道報文段M3沒有到達接收方。發送方接著發送了M5和M6。接收方收到這兩個報文后,也還要再次發出對M2的重復確認。這樣,發送方共收到了 接收方的四個對M2的確認,其中后三個都是重復確認。
快重傳算法還規定,發送方只要一連收到三個重復確認就應當立即重傳對方尚未收到的報文段M3,而不必 繼續等待M3設置的重傳計時器到期。
由于發送方盡早重傳未被確認的報文段,因此采用快重傳后可以使整個網絡吞吐量提高約20%。
(2) 快恢復
與快重傳配合使用的還有快恢復算法,其過程有以下兩個要點:
當發送方連續收到三個重復確認,就執行“乘法減小”算法,把慢開始門限ssthresh減半。
與慢開始不同之處是現在不執行慢開始算法(即擁塞窗口cwnd現在不設置為1),而是把cwnd值設置為 慢開始門限ssthresh減半后的數值,然后開始執行擁塞避免算法(“加法增大”),使擁塞窗口緩慢地線性增大。
相關文章



 關閉
關閉