
您當(dāng)前位置: 主頁 > 資訊動(dòng)態(tài) > IT知識(shí)庫 >
IT安全運(yùn)維| 數(shù)據(jù)防泄露DLP簡(jiǎn)介
2020-05-10 18:45 作者:艾銻無限 瀏覽量:
在企業(yè)IT運(yùn)維中提到數(shù)據(jù)保護(hù),大家可能常常想起文檔,很少有人會(huì)關(guān)注文檔中的內(nèi)容,對(duì)數(shù)據(jù)的管理也比較單一,通常就是全加密、全授權(quán),對(duì)文檔的重要性不做區(qū)分,隨著社會(huì)的發(fā)展,文檔的格式越來越多,安全事件的不斷爆發(fā),使得人們對(duì)數(shù)據(jù)的關(guān)注度發(fā)生了變化,數(shù)據(jù)也分成了結(jié)構(gòu)化數(shù)據(jù)和非結(jié)構(gòu)化數(shù)據(jù),更加的關(guān)注文檔內(nèi)容中的敏感信息,使用文檔的應(yīng)用有哪些,對(duì)不同類型的文檔、含有不同內(nèi)容的文檔有區(qū)別的管理和存儲(chǔ)。以前要管控?cái)?shù)據(jù),大多是強(qiáng)管控,直接全部隔離,或者全部加密,我們稱之為囚籠、枷鎖式的管控,在實(shí)際的數(shù)據(jù)生產(chǎn)、使用、流轉(zhuǎn)中帶來了很多不必要的麻煩,人們需要更加靈活的方式來處理數(shù)據(jù),此時(shí),智能化的數(shù)據(jù)安全管控應(yīng)運(yùn)而生,企業(yè)IT運(yùn)維可以按照數(shù)據(jù)的重要程度有針對(duì)性的對(duì)數(shù)據(jù)進(jìn)行控制。數(shù)據(jù)防泄漏的核心能力
什么是DLP呢?字面上翻譯為“Data Leakage(Loss) Prevention數(shù)據(jù)泄露防護(hù)”,其核心能力就是內(nèi)容識(shí)別,通過識(shí)別可以擴(kuò)展到對(duì)數(shù)據(jù)的防控。內(nèi)容識(shí)別應(yīng)該具備的識(shí)別能力具體來說有關(guān)鍵字、正則表達(dá)式、文檔指紋、確切數(shù)據(jù)源(數(shù)據(jù)庫指紋)、支持向量機(jī),針對(duì)于每一種能力又會(huì)衍伸出多種復(fù)合能力。DLP還應(yīng)該具備防護(hù)能力,防護(hù)范圍包括網(wǎng)絡(luò)防護(hù)和終端防護(hù)。網(wǎng)絡(luò)防護(hù)主要以審計(jì)、控制為主,終端防護(hù)除審計(jì)與控制能力外,還應(yīng)包含傳統(tǒng)的主機(jī)控制能力、加密和權(quán)限控制能力。總的來說,DLP其實(shí)就是一個(gè)綜合體,最終實(shí)現(xiàn)的效果,應(yīng)該是智能發(fā)現(xiàn)、智能加密、智能管控、智能審計(jì),也是一整套的數(shù)據(jù)泄露防護(hù)方案。
數(shù)據(jù)防泄漏的組件構(gòu)成
下圖說明DLP的實(shí)體配置,以及不同模型在組織內(nèi)的常駐位置。“網(wǎng)絡(luò) DLP”產(chǎn)品常駐于 DMZ 中,而其他產(chǎn)品則常駐于企業(yè) LAN 或數(shù)據(jù)中心。 除了“終端 DLP”產(chǎn)品以外,所有其他產(chǎn)品都是以服務(wù)器為基礎(chǔ)。
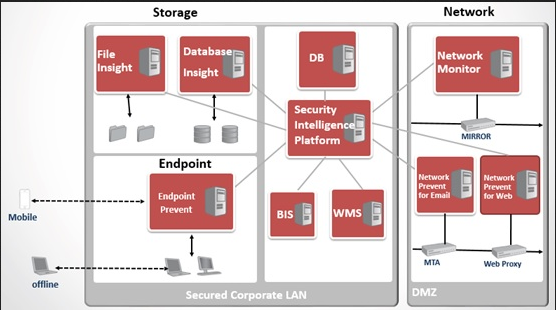
為了預(yù)防數(shù)據(jù)丟失,無論數(shù)據(jù)的存儲(chǔ)、復(fù)制或傳輸位置在哪里,都必須準(zhǔn)確地檢測(cè)所有類型的機(jī)密數(shù)據(jù)。如果沒有準(zhǔn)確的檢測(cè),數(shù)據(jù)安全系統(tǒng)就會(huì)生成許多誤報(bào) (將并未違規(guī)的消息或文件標(biāo)識(shí)為違規(guī)) 以及漏報(bào) (未將違反策略的消息或文件標(biāo)識(shí)為違規(guī))。誤報(bào)會(huì)大量耗費(fèi)進(jìn)行進(jìn)一步調(diào)查和解決明顯事故所需的時(shí)間和資源。漏報(bào)會(huì)掩蓋安全漏洞,導(dǎo)致數(shù)據(jù)丟失、潛在財(cái)務(wù)損失、法律風(fēng)險(xiǎn)并有損組織聲譽(yù)。因此需要準(zhǔn)確的檢測(cè)技術(shù)來做保障。為了確保最高的準(zhǔn)確性,DLP 采用了三種基礎(chǔ)檢測(cè)技術(shù)和三種高級(jí)檢測(cè)技術(shù)。
1、基礎(chǔ)檢測(cè)技術(shù)
基礎(chǔ)檢測(cè)技術(shù)中通常有三種方式,正則表達(dá)式檢測(cè)(標(biāo)示符)、關(guān)鍵字和關(guān)鍵字對(duì)檢測(cè)、文檔屬性檢測(cè)。基礎(chǔ)檢測(cè)方法采用常規(guī)的檢測(cè)技術(shù)進(jìn)行內(nèi)容搜索和匹配,比較常見的都是正則表達(dá)式和關(guān)鍵字,此兩種方法可以對(duì)明確的敏感信息內(nèi)容進(jìn)行檢測(cè);文檔屬性檢測(cè)主要是針對(duì)文檔的類型、文檔的大小、文檔的名稱進(jìn)行檢測(cè),其中文檔的類型的檢測(cè)是基于文件格式進(jìn)行檢測(cè),不是簡(jiǎn)單的基于后綴名檢測(cè),對(duì)于修改后綴名的場(chǎng)景,文件類型檢測(cè)可以準(zhǔn)確的檢測(cè)出被檢測(cè)文件的類型,目前支持100多種標(biāo)準(zhǔn)的文件類型,并且可以通過自定義特征,去識(shí)別特殊的文件類型格式的文檔。
2、高級(jí)檢測(cè)技術(shù)
高級(jí)檢測(cè)技術(shù)中也有三種方式,精確數(shù)據(jù)比對(duì) (EDM)、指紋文檔比對(duì) (IDM)、向量分類比對(duì) (SVM)。EDM 用于保護(hù)通常為結(jié)構(gòu)化格式的數(shù)據(jù),例如客戶或員工數(shù)據(jù)庫記錄。IDM和SVM 用于保護(hù)非結(jié)構(gòu)化的數(shù)據(jù),例如 Microsoft Word 或 PowerPoint 文檔。對(duì)于 EDM、IDM、SVM 而言,敏感數(shù)據(jù)會(huì)先由企業(yè)標(biāo)識(shí)出來,然后再由DLP判別其特征,以進(jìn)行精準(zhǔn)的持續(xù)檢測(cè)。判別特征的流程包括DLP訪問和檢索文本及數(shù)據(jù)、予以正規(guī)化,并使用不可逆的打亂方式進(jìn)行保護(hù)。
DLP 檢測(cè)是以實(shí)際的機(jī)密內(nèi)容為基礎(chǔ),而非根據(jù)文件本身。因此,DLP不只能檢測(cè)敏感數(shù)據(jù)的檢索項(xiàng)或衍生項(xiàng),而且能夠標(biāo)識(shí)文件格式與特征信息格式不同的敏感數(shù)據(jù)。例如,如果已經(jīng)判別出機(jī)密 Microsoft Word 文檔的特征,DLP就能夠在相同的內(nèi)容以 PDF 附件的方式通過電子郵件進(jìn)行提交時(shí),將其準(zhǔn)確檢測(cè)出來。
(1)精確數(shù)據(jù)比對(duì)
精確數(shù)據(jù)比對(duì) (EDM) 可保護(hù)客戶與員工的數(shù)據(jù),以及其他通常存儲(chǔ)在數(shù)據(jù)庫中的結(jié)構(gòu)化數(shù)據(jù)。例如,客戶可能會(huì)撰寫有關(guān)使用 EDM 檢測(cè)的策略,以在消息中查找“名字”、“身份證號(hào)”、“銀行帳號(hào)”或“電話號(hào)碼”其中任意三項(xiàng)同時(shí)出現(xiàn)的情況,并將其映射至客戶數(shù)據(jù)庫中的記錄。EDM 允許根據(jù)特定數(shù)據(jù)列中的任何數(shù)據(jù)欄組合進(jìn)行檢測(cè);也就是在特定記錄中檢測(cè) M 個(gè)字段中的 N 個(gè)字段。它能夠在“值組”或指定的數(shù)據(jù)類型集上觸發(fā);例如,可接受名字與身份證號(hào)這兩個(gè)字段的組合,但不接受名字與手機(jī)號(hào)這兩個(gè)字段的組合。由于會(huì)針對(duì)每個(gè)數(shù)據(jù)存儲(chǔ)格存儲(chǔ)一個(gè)單獨(dú)的打亂號(hào)碼,因此只有來自單個(gè)列的映射數(shù)據(jù)才能觸發(fā)正在查找不同數(shù)據(jù)組合的檢測(cè)策略。例如,有個(gè)EDM 策略請(qǐng)求“名字+ 身份證號(hào)+手機(jī)號(hào)”的組合,則“張三”+“13333333333”“110001198107011533” 可觸發(fā)此策略,但是即使 “李四”也位于同一數(shù)據(jù)庫中,“李四”+“13333333333”“110001198107011533”也不能觸發(fā)此策略。EDM 也支持相近邏輯以減少可能的誤報(bào)情形。對(duì)于檢測(cè)期間所處理的自由格式文本而言,單個(gè)特征列中所有數(shù)據(jù)各自的字?jǐn)?shù)均必須在可配置的范圍內(nèi),方可視為匹配項(xiàng)。例如,依默認(rèn),在檢測(cè)到的電子郵件正文的文本中,“張三”+“13333333333”“110001198107011533”各自的字?jǐn)?shù)必須在選定的范圍內(nèi),才會(huì)出現(xiàn)匹配項(xiàng)。對(duì)于含有表式數(shù)據(jù) (例如 Excel 電子表格) 的文本而言,單個(gè)特征列中所有數(shù)據(jù)都必須位于表式文本的同一行上,方可視為匹配項(xiàng),以減少整體誤報(bào)情形。
(2)指紋文檔比對(duì)
“指紋文檔比對(duì)”(IDM) 可確保準(zhǔn)確檢測(cè)以文檔形式存儲(chǔ)的非結(jié)構(gòu)化數(shù)據(jù),例如 Microsoft Word 與 PowerPoint 文件、PDF 文檔、財(cái)務(wù)、并購文檔,以及其他敏感或?qū)S行畔ⅰDM 會(huì)創(chuàng)建文檔指紋特征,以檢測(cè)原始文檔的已檢索部分、草稿或不同版本的受保護(hù)文檔。IDM 首先要進(jìn)行敏感文件的學(xué)習(xí)和訓(xùn)練,拿到敏感內(nèi)容的文檔時(shí), IDM采用語義分析的技術(shù)進(jìn)行分詞,然后進(jìn)行語義分析,提出來需要學(xué)習(xí)和訓(xùn)練的敏感信息文檔的指紋模型,然后利用同樣的方法對(duì)被測(cè)的文檔或內(nèi)容進(jìn)行指紋抓取,將得到的指紋與訓(xùn)練的指紋進(jìn)行比對(duì),根據(jù)預(yù)設(shè)的相似度去確認(rèn)被檢測(cè)文檔是否為敏感信息文檔。這種方法可讓 IDM 具備極高的準(zhǔn)確率與較大的擴(kuò)展性。
(3)向量機(jī)分類比對(duì)
支持向量機(jī)(Support Vector Machines)是由Vapnik等人于1995年提出來的。之后隨著統(tǒng)計(jì)理論的發(fā)展,支持向量機(jī)也逐漸受到了各領(lǐng)域研究者的關(guān)注,在很短的時(shí)間就得到很廣泛的應(yīng)用。支持向量機(jī)是建立在統(tǒng)計(jì)學(xué)習(xí)理論的VC維理論和結(jié)構(gòu)風(fēng)險(xiǎn)最小化原理基礎(chǔ)上的,利用有限的樣本所提供的信息對(duì)模型的復(fù)雜性和學(xué)習(xí)能力兩者進(jìn)行了尋求最佳的折中,以獲得最好的泛化能力。SVM的基本思想是把訓(xùn)練數(shù)據(jù)非線性的映射到一個(gè)更高維的特征空間(Hilbert空間)中,在這個(gè)高維的特征空間中尋找到一個(gè)超平面使得正例和反例兩者間的隔離邊緣被最大化。SVM的出現(xiàn)有效的解決了傳統(tǒng)的神經(jīng)網(wǎng)絡(luò)結(jié)果選擇問題、局部極小值、過擬合等問題。并且在小樣本、非線性、數(shù)據(jù)高維等機(jī)器學(xué)習(xí)問題中表現(xiàn)出很多令人注目的性質(zhì),被廣泛地應(yīng)用在模式識(shí)別,數(shù)據(jù)挖掘等領(lǐng)域。SVM比對(duì)算法適合那些具有微妙的特征或很難描述的數(shù)據(jù),如財(cái)務(wù)報(bào)告和源代碼等。使用過程中,先將文檔按照內(nèi)容細(xì)分化分類,每一類文檔集合有屬于本類的意義,經(jīng)過SVM比對(duì),確定被檢測(cè)的文檔屬于哪一類,并取得此類文檔的權(quán)限和策略。 同時(shí),針對(duì)SVM的特點(diǎn),可以進(jìn)行終端或服務(wù)器上的文檔按照分類含義進(jìn)行分類數(shù)據(jù)發(fā)現(xiàn)。IDM和SVM的比對(duì)區(qū)別是,IDM將待檢測(cè)文件的指紋和訓(xùn)練模型中的每一個(gè)文件進(jìn)行指紋比對(duì);而SVM是將待檢測(cè)文件向量化,并歸屬到某一類訓(xùn)練集所建立的向量空間。
艾銻無限科技專業(yè):IT外包、企業(yè)外包、北京IT外包、桌面運(yùn)維、弱電工程、網(wǎng)站開發(fā)、wifi覆蓋方案,網(wǎng)絡(luò)外包,網(wǎng)絡(luò)管理服務(wù),網(wǎng)管外包,綜合布線,服務(wù)器運(yùn)維服務(wù),中小企業(yè)it外包服務(wù),服務(wù)器維保公司,硬件運(yùn)維,網(wǎng)站運(yùn)維服務(wù)
以上文章由北京艾銻無限科技發(fā)展有限公司整理
相關(guān)文章
- [網(wǎng)絡(luò)服務(wù)]保護(hù)無線網(wǎng)絡(luò)安全的十大
- [網(wǎng)絡(luò)服務(wù)]無線覆蓋 | 無線天線對(duì)信
- [網(wǎng)絡(luò)服務(wù)]綜合布線 | 綜合布線發(fā)展
- [數(shù)據(jù)恢復(fù)服務(wù)]電腦運(yùn)維技術(shù)文章:win1
- [服務(wù)器服務(wù)]串口服務(wù)器工作模式-服務(wù)
- [服務(wù)器服務(wù)]串口服務(wù)器的作用-服務(wù)維
- [服務(wù)器服務(wù)]moxa串口服務(wù)器通訊設(shè)置參
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運(yùn)維|如何臨時(shí)關(guān)閉
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運(yùn)維|如何重置IE瀏覽
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)運(yùn)維|win10系統(tǒng)升級(jí)后
- [辦公設(shè)備服務(wù)]辦公設(shè)備:VPN簡(jiǎn)介
- [辦公設(shè)備服務(wù)]辦公設(shè)備:VPN技術(shù)的要求



 關(guān)閉
關(guān)閉