
您當(dāng)前位置: 主頁 > 資訊動(dòng)態(tài) > 艾銻分享 >
IT運(yùn)維 | 分布式系統(tǒng)介紹
2020-05-10 18:05 作者:admin
IT運(yùn)維 | 分布式系統(tǒng)介紹
隨著現(xiàn)在應(yīng)用系統(tǒng)越來越龐大,數(shù)據(jù)量越來越大。單個(gè)運(yùn)算系統(tǒng)已無法滿足日益增長的計(jì)算量了。從而引入了分布式系統(tǒng)概念。作為IT運(yùn)維來講,復(fù)雜的分布式系統(tǒng)有很多抽象概念不好弄明白,今天就跟大家聊聊這個(gè)話題。
分布式系統(tǒng)是由一組通過網(wǎng)絡(luò)進(jìn)行通信、為了完成共同的任務(wù)而協(xié)調(diào)工作的計(jì)算機(jī)節(jié)點(diǎn)組成的系統(tǒng)。分布式系統(tǒng)的出現(xiàn)是為了用廉價(jià)的、普通的機(jī)器完成單個(gè)計(jì)算機(jī)無法完成的計(jì)算、存儲(chǔ)任務(wù)。其目的是利用更多的機(jī)器,處理更多的數(shù)據(jù)。首先需要明確的是,只有當(dāng)單個(gè)節(jié)點(diǎn)的處理能力無法滿足日益增長的計(jì)算、存儲(chǔ)任務(wù)的時(shí)候,且硬件的提升(加內(nèi)存、加磁盤、使用更好的CPU)高昂到得不償失的時(shí)候,應(yīng)用程序也不能進(jìn)一步優(yōu)化的時(shí)候,我們才需要考慮分布式系統(tǒng)。因?yàn)椋植际较到y(tǒng)要解決的問題本身就是和單機(jī)系統(tǒng)一樣的,而由于分布式系統(tǒng)多節(jié)點(diǎn)、通過網(wǎng)絡(luò)通信的拓?fù)浣Y(jié)構(gòu),會(huì)引入很多單機(jī)系統(tǒng)沒有的問題,為了解決這些問題又會(huì)引入更多的機(jī)制、協(xié)議,帶來更多的問題。在很多文章中,主要講分布式系統(tǒng)分為分布式計(jì)算(computation)與分布式存儲(chǔ)(storage)。計(jì)算與存儲(chǔ)是相輔相成的,計(jì)算需要數(shù)據(jù),要么來自實(shí)時(shí)數(shù)據(jù)(流數(shù)據(jù)),要么來自存儲(chǔ)的數(shù)據(jù);而計(jì)算的結(jié)果也是需要存儲(chǔ)的。在操作系統(tǒng)中,對(duì)計(jì)算與存儲(chǔ)有非常詳盡的討論,分布式系統(tǒng)只不過將這些理論推廣到多個(gè)節(jié)點(diǎn)罷了。那么分布式系統(tǒng)怎么將任務(wù)分發(fā)到這些計(jì)算機(jī)節(jié)點(diǎn)呢,很簡單的思想,分而治之,即分片(partition)。對(duì)于計(jì)算,那么就是對(duì)計(jì)算任務(wù)進(jìn)行切換,每個(gè)節(jié)點(diǎn)算一些,最終匯總就行了,這就是MapReduce的思想;對(duì)于存儲(chǔ),更好理解一下,每個(gè)節(jié)點(diǎn)存一部分?jǐn)?shù)據(jù)就行了。當(dāng)數(shù)據(jù)規(guī)模變大的時(shí)候,Partition是唯一的選擇,同時(shí)也會(huì)帶來一些好處:
(1)提升性能和并發(fā),操作被分發(fā)到不同的分片,相互獨(dú)立
(2)提升系統(tǒng)的可用性,即使部分分片不能用,其他分片不會(huì)受到影響
理想的情況下,有分片就行了,但事實(shí)的情況卻不大理想。原因在于,分布式系統(tǒng)中有大量的節(jié)點(diǎn),且通過網(wǎng)絡(luò)通信。單個(gè)節(jié)點(diǎn)的故障(進(jìn)程crash、斷電、磁盤損壞)是個(gè)小概率事件,但整個(gè)系統(tǒng)的故障率會(huì)隨節(jié)點(diǎn)的增加而指數(shù)級(jí)增加,網(wǎng)絡(luò)通信也可能出現(xiàn)斷網(wǎng)、高延遲的情況。在這種一定會(huì)出現(xiàn)的“異常”情況下,分布式系統(tǒng)還是需要繼續(xù)穩(wěn)定的對(duì)外提供服務(wù),即需要較強(qiáng)的容錯(cuò)性。最簡單的辦法,就是冗余或者復(fù)制集(Replication),即多個(gè)節(jié)點(diǎn)負(fù)責(zé)同一個(gè)任務(wù),最為常見的就是分布式存儲(chǔ)中,多個(gè)節(jié)點(diǎn)復(fù)雜存儲(chǔ)同一份數(shù)據(jù),以此增強(qiáng)可用性與可靠性。同時(shí),Replication也會(huì)帶來性能的提升,比如數(shù)據(jù)的locality可以減少用戶的等待時(shí)間。
下面這張圖形象生動(dòng)說明了Partition與Replication是如何協(xié)作的。
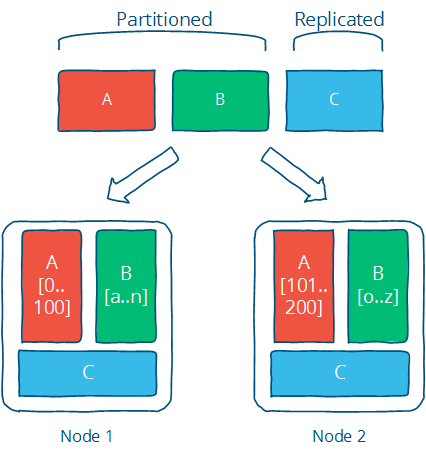
分布式系統(tǒng)挑戰(zhàn)
分布式系統(tǒng)需要大量機(jī)器協(xié)作,面臨諸多的挑戰(zhàn):
第一,異構(gòu)的機(jī)器與網(wǎng)絡(luò):
分布式系統(tǒng)中的機(jī)器,配置不一樣,其上運(yùn)行的服務(wù)也可能由不同的語言、架構(gòu)實(shí)現(xiàn),因此處理能力也不一樣;節(jié)點(diǎn)間通過網(wǎng)絡(luò)連接,而不同網(wǎng)絡(luò)運(yùn)營商提供的網(wǎng)絡(luò)的帶寬、延時(shí)、丟包率又不一樣。怎么保證大家齊頭并進(jìn),共同完成目標(biāo),這四個(gè)不小的挑戰(zhàn)。
第二,普遍的節(jié)點(diǎn)故障:
雖然單個(gè)節(jié)點(diǎn)的故障概率較低,但節(jié)點(diǎn)數(shù)目達(dá)到一定規(guī)模,出故障的概率就變高了。分布式系統(tǒng)需要保證故障發(fā)生的時(shí)候,系統(tǒng)仍然是可用的,這就需要監(jiān)控節(jié)點(diǎn)的狀態(tài),在節(jié)點(diǎn)故障的情況下將該節(jié)點(diǎn)負(fù)責(zé)的計(jì)算、存儲(chǔ)任務(wù)轉(zhuǎn)移到其他節(jié)點(diǎn)
第三,不可靠的網(wǎng)絡(luò):
節(jié)點(diǎn)間通過網(wǎng)絡(luò)通信,而網(wǎng)絡(luò)是不可靠的。可能的網(wǎng)絡(luò)問題包括:網(wǎng)絡(luò)分割、延時(shí)、丟包、亂序。相比單機(jī)過程調(diào)用,網(wǎng)絡(luò)通信最讓人頭疼的是超時(shí):節(jié)點(diǎn)A向節(jié)點(diǎn)B發(fā)出請(qǐng)求,在約定的時(shí)間內(nèi)沒有收到節(jié)點(diǎn)B的響應(yīng),那么B是否處理了請(qǐng)求,這個(gè)是不確定的,這個(gè)不確定會(huì)帶來諸多問題,最簡單的,是否要重試請(qǐng)求,節(jié)點(diǎn)B會(huì)不會(huì)多次處理同一個(gè)請(qǐng)求。
總而言之,分布式的挑戰(zhàn)來自不確定性,不確定計(jì)算機(jī)什么時(shí)候crash、斷電,不確定磁盤什么時(shí)候損壞,不確定每次網(wǎng)絡(luò)通信要延遲多久,也不確定通信對(duì)端是否處理了發(fā)送的消息。而分布式的規(guī)模放大了這個(gè)不確定性,不確定性是令人討厭的,所以有諸多的分布式理論、協(xié)議來保證在這種不確定性的情況下,系統(tǒng)還能繼續(xù)正常工作。
以上內(nèi)容由北京艾銻無限科技發(fā)展有限公司整理
相關(guān)文章
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)絡(luò)虛擬化的未來發(fā)展趨
- [網(wǎng)絡(luò)服務(wù)]好用的VPN有哪些(分類)
- [網(wǎng)絡(luò)服務(wù)]什么是vpn-無線覆蓋
- [桌面服務(wù)]電腦如何設(shè)置休眠不斷網(wǎng)
- [網(wǎng)絡(luò)服務(wù)]網(wǎng)線接口燈不亮了怎么辦
- [服務(wù)器服務(wù)]IT安全運(yùn)維_幾個(gè)常見web漏
- [網(wǎng)絡(luò)服務(wù)]VLAN配置-網(wǎng)絡(luò)運(yùn)維
- [網(wǎng)絡(luò)服務(wù)]LAN配置-網(wǎng)絡(luò)運(yùn)維
- [辦公設(shè)備服務(wù)]復(fù)印機(jī)的準(zhǔn)備工作-辦公設(shè)
- [辦公設(shè)備服務(wù)]數(shù)碼復(fù)印機(jī)的優(yōu)點(diǎn)-辦公設(shè)
- [辦公設(shè)備服務(wù)]數(shù)碼復(fù)印機(jī)的工作原理-辦
- [網(wǎng)絡(luò)服務(wù)]查看設(shè)備狀態(tài)-網(wǎng)絡(luò)運(yùn)維



 關(guān)閉
關(guān)閉